Memory Fence
Memory fence is a type of barrier instruction that causes a CPU or compiler to enforce ordering constraint on memory operations issued before and after the memory fence instruction. This typically means that operations issued prior to the fence are guaranteed to performed before operations issued after the fence.
Memory fences are necessary because most modern CPUs employ performance optimizations that can result in out-of-order execution. This reordering of memory operations(loads and stores) normally goes unnoticed within a single thread of execution, but can cause unpredictable behavior in concurrent programs unless carefully controlled. Then, we'd like to introduce an example that would cause mistake without memory fence.
Unpredictable behavior without memory fence
When writing lock-free code in C or C++, one must often take special care to enforce correct memory ordering. Otherwise, surprising things can happen.
Intel lists several such surprises in Volume 3, §8.2.3 of their x86/64 Architecture Specification. Here's one of the simplest examples. Suppose you have four integers r1, r2, X and Y somewhere in memory, both initially 0. Two processors, running in parallel, execute the following memory operations:
 It's really the best way to illustrate CPU ordering. Each processor stores 1 to
It's really the best way to illustrate CPU ordering. Each processor stores 1 to X and Y respectively, then processor 1 assigns the value of integer Y to integer r1, and processor 2 assigns the value of X to integer r2. Now, no matter which processor writes 1 to memory(X or Y) first, it's natural to expect the other processor to read that value back, which means we should end up with either r1 = 1, r2 = 1, or perhaps both. But according to Intel's specification, that won't necessarily be the case. The specification says it's legal for both r1 and r2 to equal 0 at the end of this example -- a counter-intuitive result, to say at least.
One way to understand this is that Intel x86/64 processors, like most out-of-order processor families, are allowed to reorder the memory operations according to certain rules. For instance, processor 1 can executes operation r1 = Y first, then executes X = 1. The table below shows an extreme circumstance:
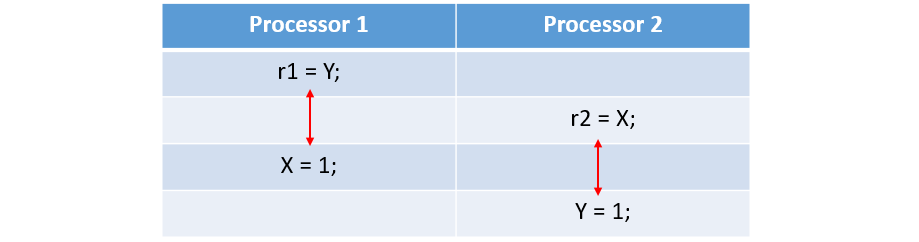
Both processor 1 and processor 2 reorder the memory operations. And processor 2 executes r2 = X before processor 1 executes X = 1 resulting at that both r1 and r2 to be 0.
It's all well and good to be told this kind of thing might happen, but there's nothing like seeing it with your own eyes. That's why we've written a small sample program to show this type of reordering actually happening.
ordering.c:
#include<pthread.h>
#include<stdlib.h>
#include<semaphore.h>
#include<stdio.h>
// Set it to 1 to prevent CPU reordering
#define USE_CPU_FENCE 0
/*
* Main program
*/
sem_t beginSema1;
sem_t beginSema2;
sem_t endSema;
int X, Y;
int r1, r2;
void * thread1Func(void* param);
void * thread2Func(void* param);
int main()
{
// Initialize the semaphores
sem_init(&beginSema1, 0, 0);
sem_init(&beginSema2, 0, 0);
sem_init(&endSema, 0, 0);
int ID1 = 1;
int ID2 = 2;
// Spawn the threads
pthread_t thread1, thread2;
pthread_create(&thread1, NULL, thread1Func, (void*)&ID1);
pthread_create(&thread2, NULL, thread2Func, (void*)&ID2);
// Repeat the experiment ad infinitum
int detected = 0;
for(int iterations = 1; ; iterations++){
// Reset X and Y
X = 0;
Y = 0;
// Signal both threads
sem_post(&beginSema1);
sem_post(&beginSema2);
// Wait for both threads
sem_wait(&endSema);
sem_wait(&endSema);
// Check if there was a simultaneous reorder
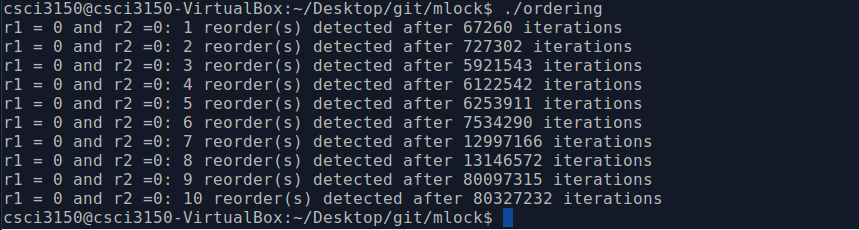
if(r1 == 0 && r2 == 0){
detected ++;
printf("r1 = 0 and r2 =0: %d reorder(s) detected after %d iterations\n",
detected, iterations);
}
if(detected == 10)
break;
}
return 0;
}
void * thread1Func(void * param){
// Endless loop
int * ID = (int*) param;
for(;;) {
sem_wait(&beginSema1); // Wait for signal
while(rand_r(ID) % 8 != 0){} // Random delay
//-------- THE TRANSACTION!-------
X = 1;
# if USE_CPU_FENCE
asm volatile("mfence":::"memory"); // Prevent CPU reordering
# else
asm volatile("":::"memory"); // Prevent compiler reordering
# endif
r1 = Y;
sem_post(&endSema); // Notify transaction complete
}
return NULL; // Never returns
}
void * thread2Func(void * param){
int * ID = (int*) param;
for(;;){
sem_wait(&beginSema2);
while(rand_r(ID) % 8 != 0){}
// ---- THE TRANSACTION! ----
Y = 1;
# if USE_CPU_FENCE
asm volatile("mfence":::"memory");
# else
asm volatile("":::"memory");
# endif
r2 = X;
sem_post(&endSema);
}
return NULL;
}
As you can see in ordering.c, X, Y, r1, r2 are all global variables, and POSIX semaphores are used to co-ordinate the beginning and the end of each loop. Besides, we define USE_CPU_FENCE as 0, it means that we would not use memory fence. To prevent compiler reordering, we also embed assembly code in the C program.
To build and run the example:
$ gcc ordering.c -o ordering -O2 -lpthread
Please note that, when running ordering , you must set your own virtual machine with 2 cores.
Usage of memory fence
In order to prevent unpredictable behavior like above example shows, we can set memory fence instruction between memory operations. In ordering.c, you can replace #define USE_CPU_FENCE 0with#define USE_CPU_FENCE 1. In this way, the compiler will insert the memory fence instruction both between X = 1 and r1 = Y, and between Y = 1 andr2 = X. So, processor 1 must issue memory operation X = 1 before r1 = Y, and processor 2 must issue operation Y = 1 before r2 = X. With this modification, the memory operation reordering disappears.
references